Showing
- contributions/sdds-xdc/artifact/SDDS-XDC.pdf 0 additions, 0 deletionscontributions/sdds-xdc/artifact/SDDS-XDC.pdf
- contributions/sdds-xdc/artifact/iopams.sty 87 additions, 0 deletionscontributions/sdds-xdc/artifact/iopams.sty
- contributions/sdds-xdc/artifact/jpconf.cls 957 additions, 0 deletionscontributions/sdds-xdc/artifact/jpconf.cls
- contributions/sdds-xdc/artifact/jpconf11.clo 141 additions, 0 deletionscontributions/sdds-xdc/artifact/jpconf11.clo
- contributions/storage/.gitkeep 0 additions, 0 deletionscontributions/storage/.gitkeep
- contributions/storage/danni.PNG 0 additions, 0 deletionscontributions/storage/danni.PNG
- contributions/storage/storage.tex 243 additions, 0 deletionscontributions/storage/storage.tex
- contributions/summerstudent/.gitkeep 0 additions, 0 deletionscontributions/summerstudent/.gitkeep
- contributions/summerstudent/MLalgorithms.png 0 additions, 0 deletionscontributions/summerstudent/MLalgorithms.png
- contributions/summerstudent/StoRM-full-picture.png 0 additions, 0 deletionscontributions/summerstudent/StoRM-full-picture.png
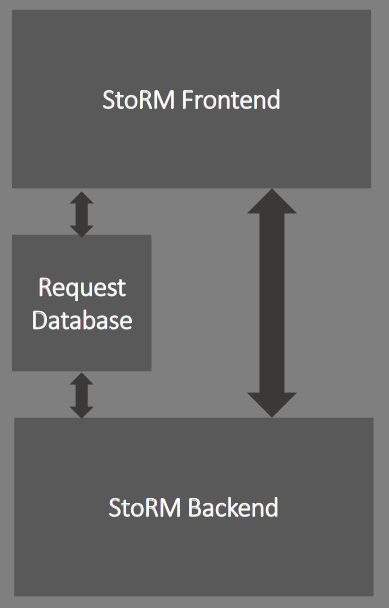
- contributions/summerstudent/StoRM.png 0 additions, 0 deletionscontributions/summerstudent/StoRM.png
- contributions/summerstudent/kibana.png 0 additions, 0 deletionscontributions/summerstudent/kibana.png
- contributions/summerstudent/summerstudent.tex 90 additions, 0 deletionscontributions/summerstudent/summerstudent.tex
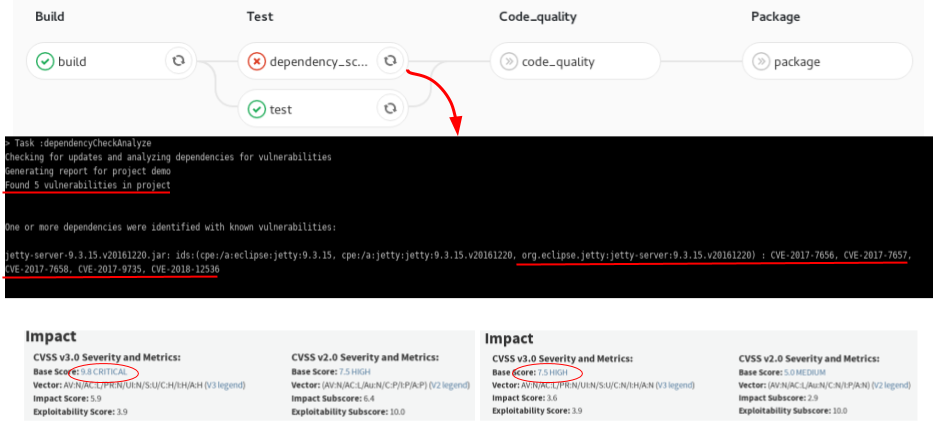
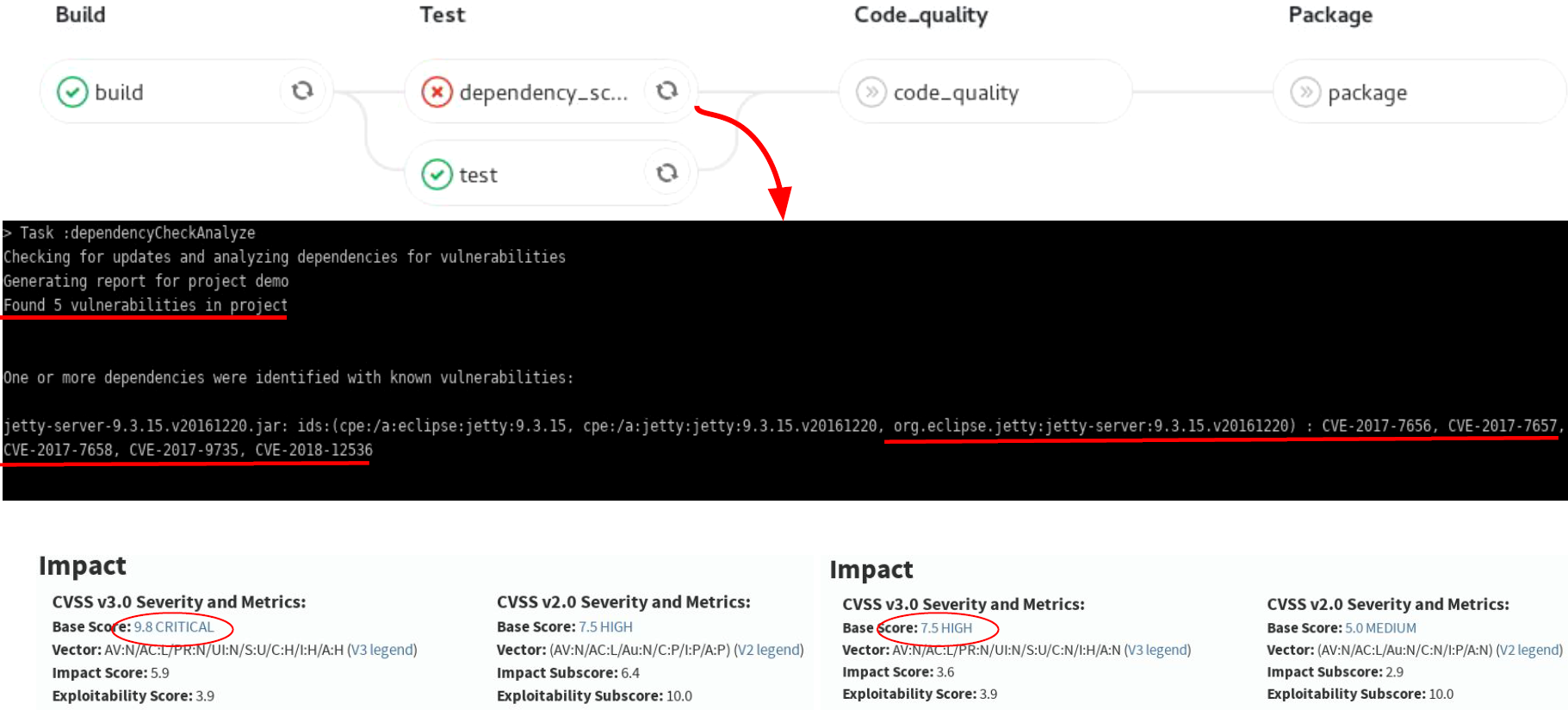
- contributions/sysinfo/deps_scan.png 0 additions, 0 deletionscontributions/sysinfo/deps_scan.png
- contributions/sysinfo/sysinfo.tex 66 additions, 40 deletionscontributions/sysinfo/sysinfo.tex
- contributions/tier1/.gitkeep 0 additions, 0 deletionscontributions/tier1/.gitkeep
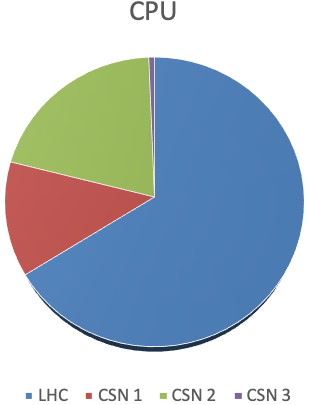
- contributions/tier1/cpu2018.png 0 additions, 0 deletionscontributions/tier1/cpu2018.png
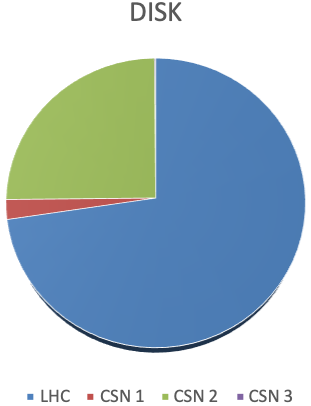
- contributions/tier1/disk2018.png 0 additions, 0 deletionscontributions/tier1/disk2018.png
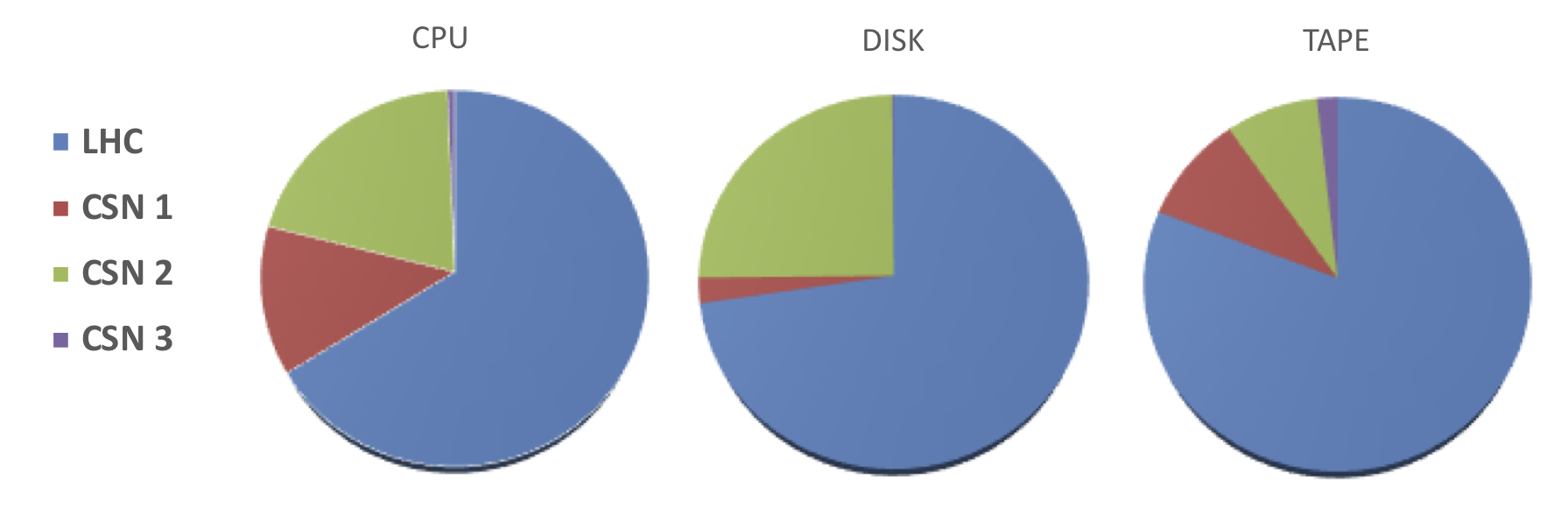
- contributions/tier1/pledge.png 0 additions, 0 deletionscontributions/tier1/pledge.png
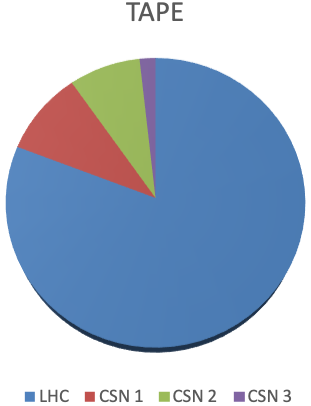
- contributions/tier1/tape2018.png 0 additions, 0 deletionscontributions/tier1/tape2018.png
contributions/sdds-xdc/artifact/SDDS-XDC.pdf
0 → 100644
File added
contributions/sdds-xdc/artifact/iopams.sty
0 → 100644
contributions/sdds-xdc/artifact/jpconf.cls
0 → 100644
contributions/sdds-xdc/artifact/jpconf11.clo
0 → 100644
contributions/storage/.gitkeep
0 → 100644
contributions/storage/danni.PNG
0 → 100644
{kind=link}

1.52 MiB
contributions/storage/storage.tex
0 → 100644
contributions/summerstudent/.gitkeep
0 → 100644
contributions/summerstudent/MLalgorithms.png
0 → 100644
{kind=link}

25.4 KiB
{kind=link}

381 KiB
contributions/summerstudent/StoRM.png
0 → 100644
{kind=link}
17 KiB
contributions/summerstudent/kibana.png
0 → 100644
{kind=link}

388 KiB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
contributions/tier1/.gitkeep
0 → 100644
contributions/tier1/cpu2018.png
0 → 100644
{kind=link}
27.8 KiB
contributions/tier1/disk2018.png
0 → 100644
{kind=link}
28.4 KiB
contributions/tier1/pledge.png
0 → 100644
{kind=link}
180 KiB
contributions/tier1/tape2018.png
0 → 100644
{kind=link}
30.2 KiB