Showing
- contributions/cuore/cuore.tex 73 additions, 0 deletionscontributions/cuore/cuore.tex
- contributions/cupid/main.tex 6 additions, 3 deletionscontributions/cupid/main.tex
- contributions/dampe/main.tex 21 additions, 17 deletionscontributions/dampe/main.tex
- contributions/darkside/.gitkeep 0 additions, 0 deletionscontributions/darkside/.gitkeep
- contributions/darkside/ds-annual-report-2019.tex 72 additions, 0 deletionscontributions/darkside/ds-annual-report-2019.tex
- contributions/datacenter/datacenter.pdf 0 additions, 0 deletionscontributions/datacenter/datacenter.pdf
- contributions/dmsq/dmsq2018.tex 3 additions, 3 deletionscontributions/dmsq/dmsq2018.tex
- contributions/ds_cloud_c/Artifact/ds_cloud_c.pdf 0 additions, 0 deletionscontributions/ds_cloud_c/Artifact/ds_cloud_c.pdf
- contributions/ds_cloud_c/Artifact/iopams.sty 87 additions, 0 deletionscontributions/ds_cloud_c/Artifact/iopams.sty
- contributions/ds_cloud_c/Artifact/jpconf.cls 957 additions, 0 deletionscontributions/ds_cloud_c/Artifact/jpconf.cls
- contributions/ds_cloud_c/Artifact/jpconf11.clo 141 additions, 0 deletionscontributions/ds_cloud_c/Artifact/jpconf11.clo
- contributions/ds_cloud_c/catc_monitoring.png 0 additions, 0 deletionscontributions/ds_cloud_c/catc_monitoring.png
- contributions/ds_cloud_c/ds_cloud_c.tex 206 additions, 0 deletionscontributions/ds_cloud_c/ds_cloud_c.tex
- contributions/ds_cloud_c/infn-fe23.png 0 additions, 0 deletionscontributions/ds_cloud_c/infn-fe23.png
- contributions/ds_devops_pe/Artifact/ds_devops_pe.pdf 0 additions, 0 deletionscontributions/ds_devops_pe/Artifact/ds_devops_pe.pdf
- contributions/ds_devops_pe/Artifact/iopams.sty 87 additions, 0 deletionscontributions/ds_devops_pe/Artifact/iopams.sty
- contributions/ds_devops_pe/Artifact/jpconf.cls 957 additions, 0 deletionscontributions/ds_devops_pe/Artifact/jpconf.cls
- contributions/ds_devops_pe/Artifact/jpconf11.clo 141 additions, 0 deletionscontributions/ds_devops_pe/Artifact/jpconf11.clo
- contributions/ds_devops_pe/CI-tools.png 0 additions, 0 deletionscontributions/ds_devops_pe/CI-tools.png
- contributions/ds_devops_pe/ds_devops_pe.tex 239 additions, 0 deletionscontributions/ds_devops_pe/ds_devops_pe.tex
contributions/cuore/cuore.tex
0 → 100644
contributions/darkside/.gitkeep
0 → 100644
contributions/datacenter/datacenter.pdf
0 → 100644
File added
File added
contributions/ds_cloud_c/Artifact/iopams.sty
0 → 100644
contributions/ds_cloud_c/Artifact/jpconf.cls
0 → 100644
This diff is collapsed.
contributions/ds_cloud_c/catc_monitoring.png
0 → 100644
{kind=link}
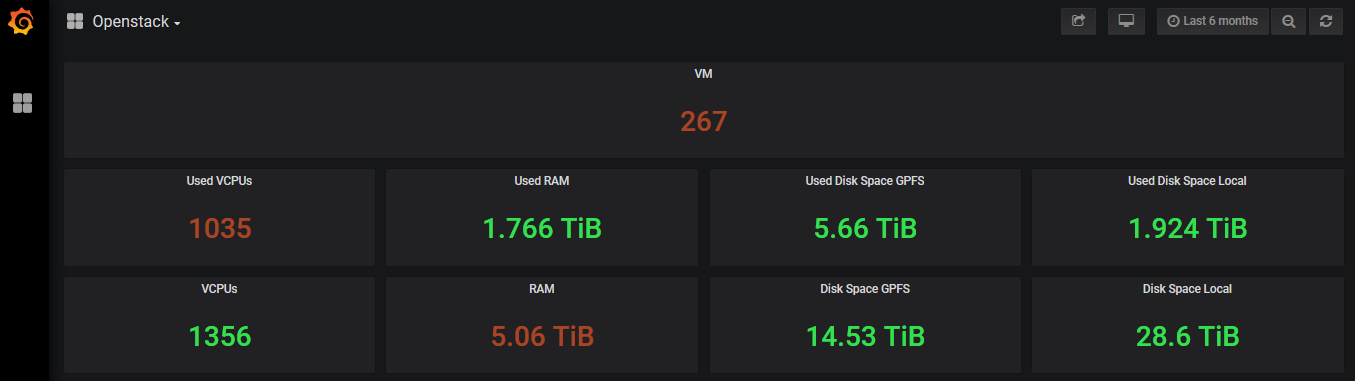
31.7 KiB
contributions/ds_cloud_c/ds_cloud_c.tex
0 → 100644
contributions/ds_cloud_c/infn-fe23.png
0 → 100644
{kind=link}
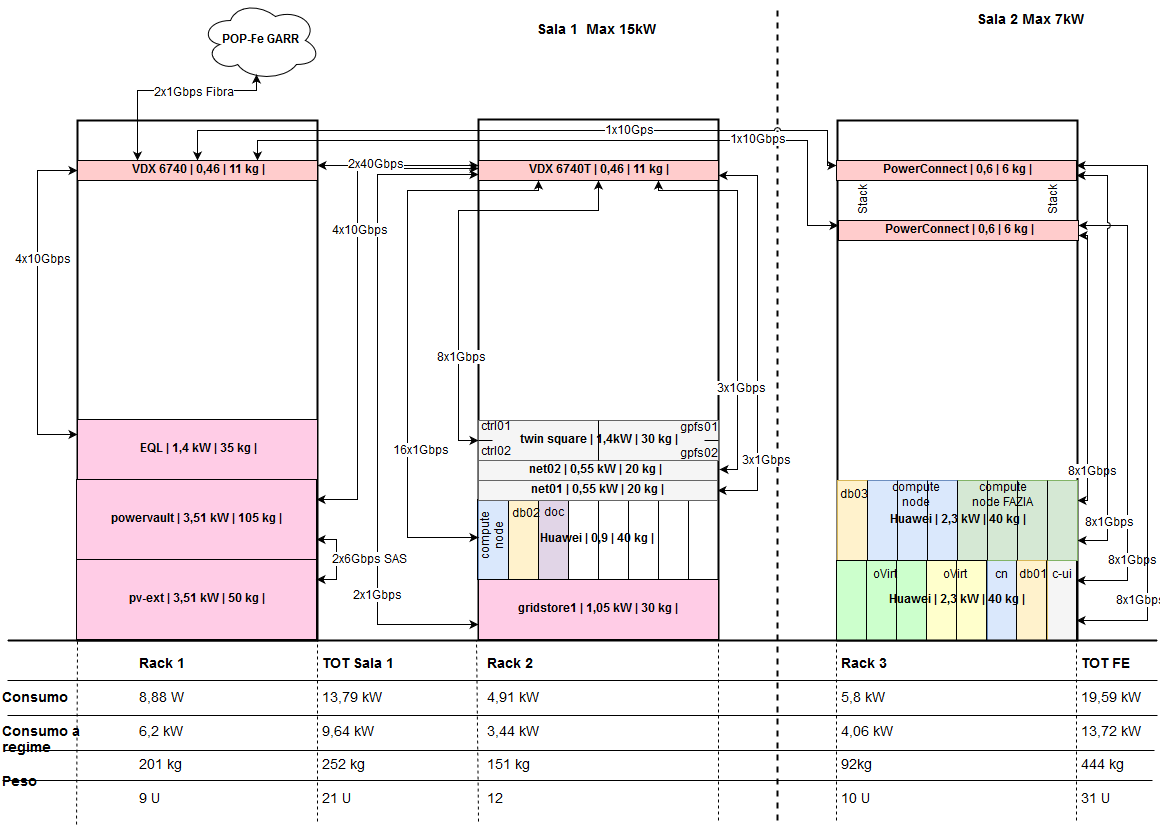
82.5 KiB
File added
This diff is collapsed.
contributions/ds_devops_pe/CI-tools.png
0 → 100644
{kind=link}
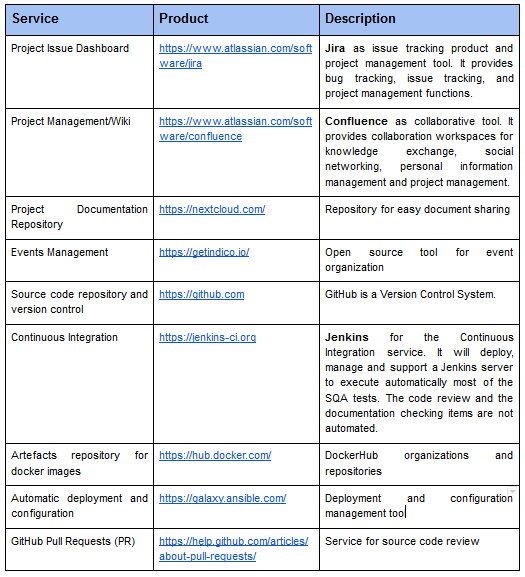
33.2 KiB
contributions/ds_devops_pe/ds_devops_pe.tex
0 → 100644