Showing
- contributions/ds_infn_cc/ds_infn_cc.tex 217 additions, 0 deletionscontributions/ds_infn_cc/ds_infn_cc.tex
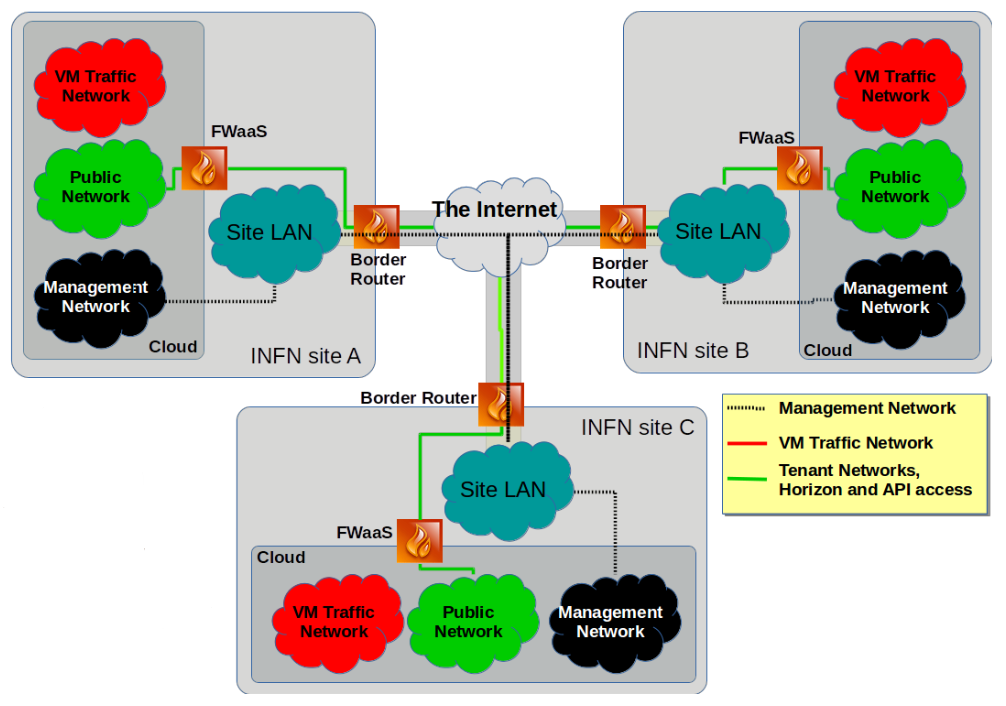
- contributions/ds_infn_cc/infncc-net.png 0 additions, 0 deletionscontributions/ds_infn_cc/infncc-net.png
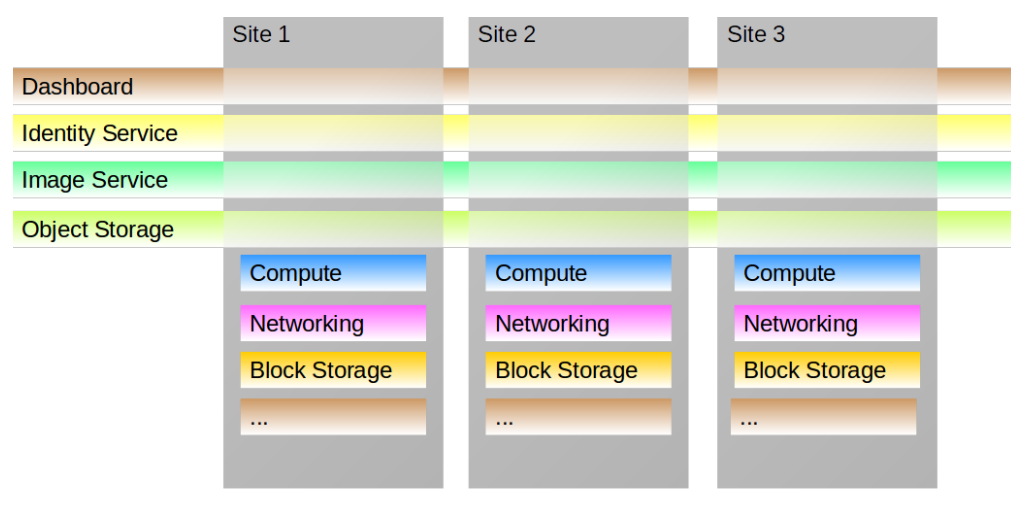
- contributions/ds_infn_cc/infncc-services.png 0 additions, 0 deletionscontributions/ds_infn_cc/infncc-services.png
- contributions/experiment/experiment.pdf 0 additions, 0 deletionscontributions/experiment/experiment.pdf
- contributions/farming/ARFarming2018.tex 223 additions, 0 deletionscontributions/farming/ARFarming2018.tex
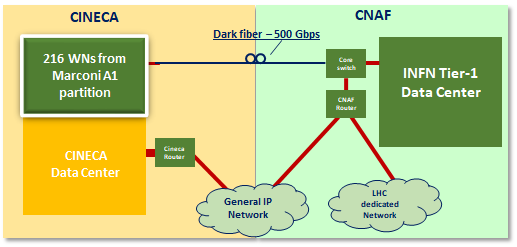
- contributions/farming/cineca.png 0 additions, 0 deletionscontributions/farming/cineca.png
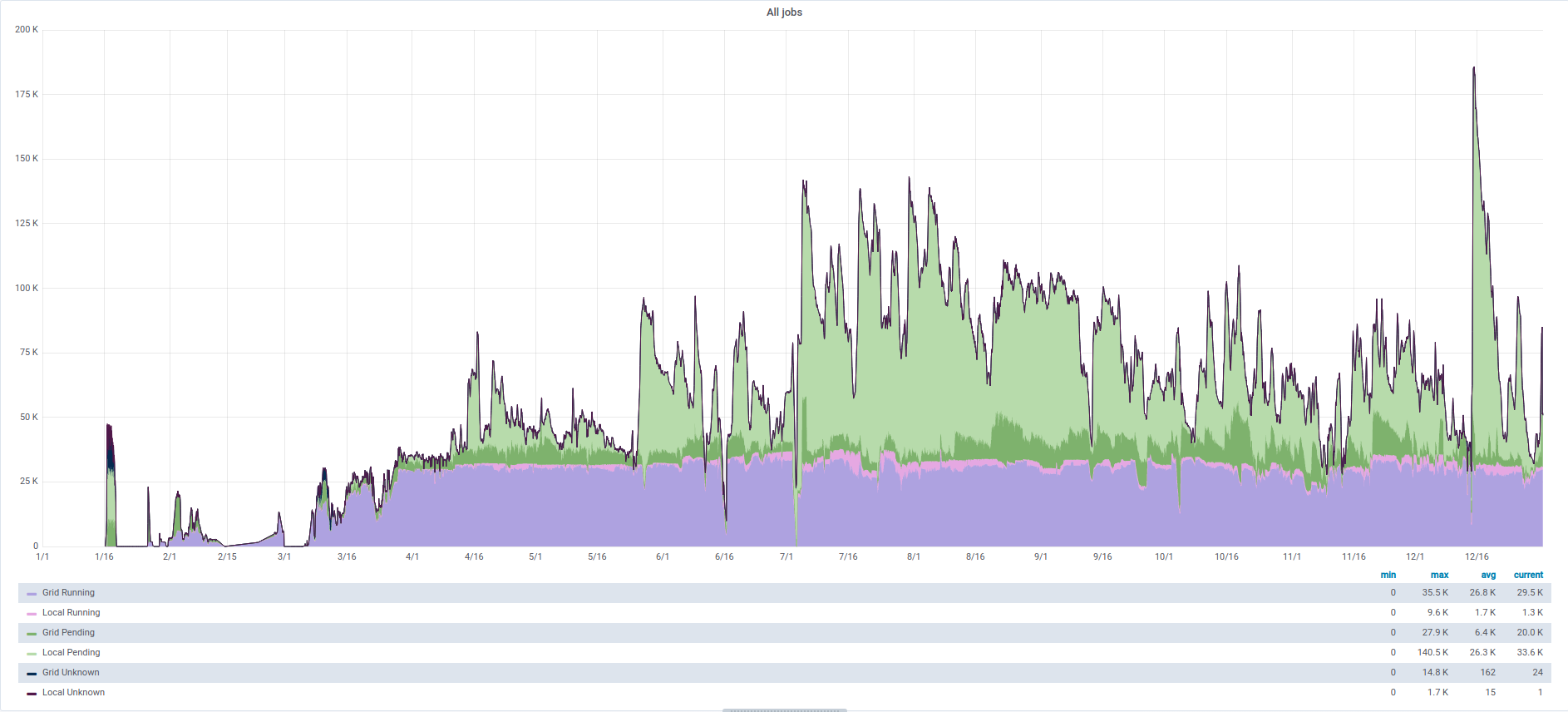
- contributions/farming/farm-jobs.png 0 additions, 0 deletionscontributions/farming/farm-jobs.png
- contributions/farming/meltdown.jpg 0 additions, 0 deletionscontributions/farming/meltdown.jpg
- contributions/farming/meltdown2.jpg 0 additions, 0 deletionscontributions/farming/meltdown2.jpg
- contributions/fermi/fermi.tex 89 additions, 0 deletionscontributions/fermi/fermi.tex
- contributions/gamma/.gitkeep 0 additions, 0 deletionscontributions/gamma/.gitkeep
- contributions/gamma/gamma.tex 79 additions, 0 deletionscontributions/gamma/gamma.tex
- contributions/icarus/ICARUS-nue-mip.png 0 additions, 0 deletionscontributions/icarus/ICARUS-nue-mip.png
- contributions/icarus/ICARUS-sterile-e1529944099665.png 0 additions, 0 deletionscontributions/icarus/ICARUS-sterile-e1529944099665.png
- contributions/icarus/SBN.png 0 additions, 0 deletionscontributions/icarus/SBN.png
- contributions/icarus/icarus-nue.png 0 additions, 0 deletionscontributions/icarus/icarus-nue.png
- contributions/icarus/report_2018.tex 259 additions, 0 deletionscontributions/icarus/report_2018.tex
- contributions/juno/.gitkeep 0 additions, 0 deletionscontributions/juno/.gitkeep
- contributions/juno/juno-annual-report-2019.pdf 0 additions, 0 deletionscontributions/juno/juno-annual-report-2019.pdf
- contributions/km3net/km3net.tex 17 additions, 18 deletionscontributions/km3net/km3net.tex
contributions/ds_infn_cc/ds_infn_cc.tex
0 → 100644
contributions/ds_infn_cc/infncc-net.png
0 → 100644
{kind=link}
198 KiB
contributions/ds_infn_cc/infncc-services.png
0 → 100644
{kind=link}
128 KiB
contributions/experiment/experiment.pdf
0 → 100644
File added
contributions/farming/ARFarming2018.tex
0 → 100644
contributions/farming/cineca.png
0 → 100644
{kind=link}
16.7 KiB
contributions/farming/farm-jobs.png
0 → 100644
{kind=link}
230 KiB
contributions/farming/meltdown.jpg
0 → 100644
{kind=link}
39.2 KiB
contributions/farming/meltdown2.jpg
0 → 100644
{kind=link}
28.5 KiB
contributions/fermi/fermi.tex
0 → 100644
contributions/gamma/.gitkeep
0 → 100644
contributions/gamma/gamma.tex
0 → 100644
contributions/icarus/ICARUS-nue-mip.png
0 → 100644
{kind=link}
106 KiB
{kind=link}
36.7 KiB
contributions/icarus/SBN.png
0 → 100644
{kind=link}
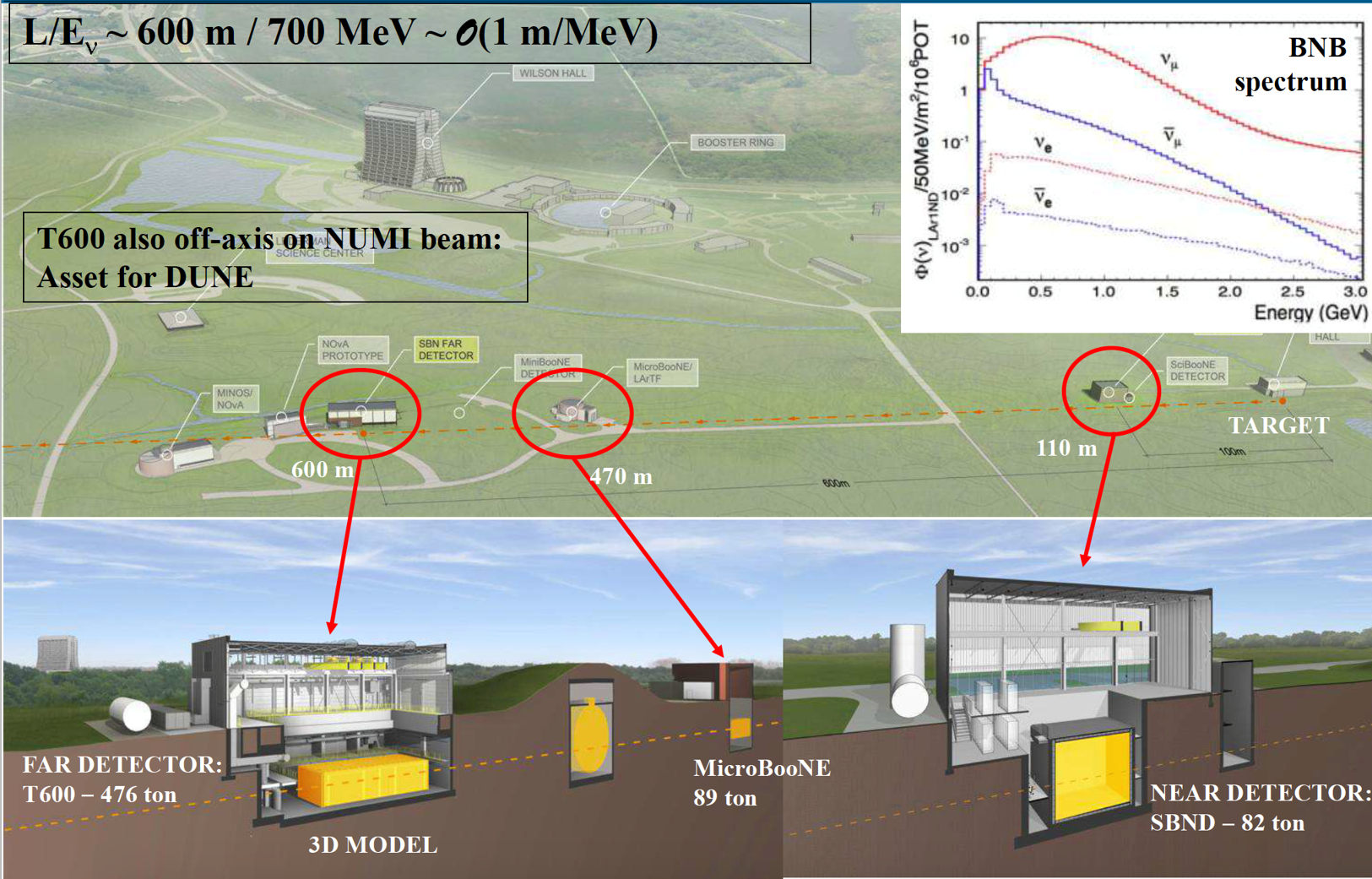
2.93 MiB
contributions/icarus/icarus-nue.png
0 → 100644
{kind=link}

476 KiB
contributions/icarus/report_2018.tex
0 → 100644
contributions/juno/.gitkeep
0 → 100644
File added