Showing
- contributions/chnet/metadataSchema.png 0 additions, 0 deletionscontributions/chnet/metadataSchema.png
- contributions/cms/report-cms-feb-2019.tex 94 additions, 93 deletionscontributions/cms/report-cms-feb-2019.tex
- contributions/cnprov/cnprov.tex 82 additions, 0 deletionscontributions/cnprov/cnprov.tex
- contributions/cnprov/cnprov.tex.bak 82 additions, 0 deletionscontributions/cnprov/cnprov.tex.bak
- contributions/cover/cover.pdf 0 additions, 0 deletionscontributions/cover/cover.pdf
- contributions/cta/CTA_ProjectTimeline_Nov2018.eps 18967 additions, 0 deletionscontributions/cta/CTA_ProjectTimeline_Nov2018.eps
- contributions/cta/CTA_annualreport_2018_v1.tex 145 additions, 0 deletionscontributions/cta/CTA_annualreport_2018_v1.tex
- contributions/cta/cpu-days-used-2018-bysite.eps 4115 additions, 0 deletionscontributions/cta/cpu-days-used-2018-bysite.eps
- contributions/cta/normalized-cpu-used-2018-bysite-cumulative.eps 4878 additions, 0 deletions...utions/cta/normalized-cpu-used-2018-bysite-cumulative.eps
- contributions/cta/transfered-data-2018-bysite.eps 5165 additions, 0 deletionscontributions/cta/transfered-data-2018-bysite.eps
- contributions/cuore/.gitkeep 0 additions, 0 deletionscontributions/cuore/.gitkeep
- contributions/cuore/cuore.bib 73 additions, 0 deletionscontributions/cuore/cuore.bib
- contributions/cuore/cuore.tex 73 additions, 0 deletionscontributions/cuore/cuore.tex
- contributions/cupid/.gitkeep 0 additions, 0 deletionscontributions/cupid/.gitkeep
- contributions/cupid/cupid-biblio.bib 114 additions, 0 deletionscontributions/cupid/cupid-biblio.bib
- contributions/cupid/main.tex 63 additions, 0 deletionscontributions/cupid/main.tex
- contributions/dampe/.gitkeep 0 additions, 0 deletionscontributions/dampe/.gitkeep
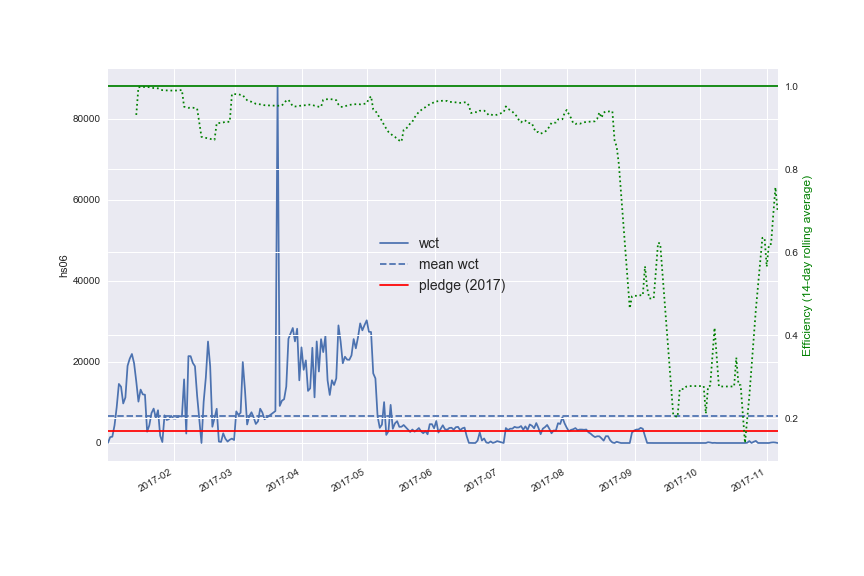
- contributions/dampe/CNAF_HS06_2017.png 0 additions, 0 deletionscontributions/dampe/CNAF_HS06_2017.png
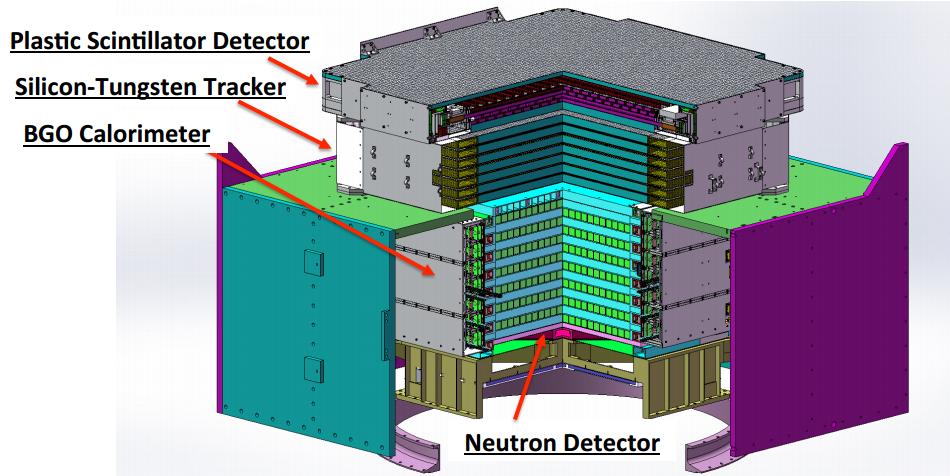
- contributions/dampe/dampe_layout_2.jpg 0 additions, 0 deletionscontributions/dampe/dampe_layout_2.jpg
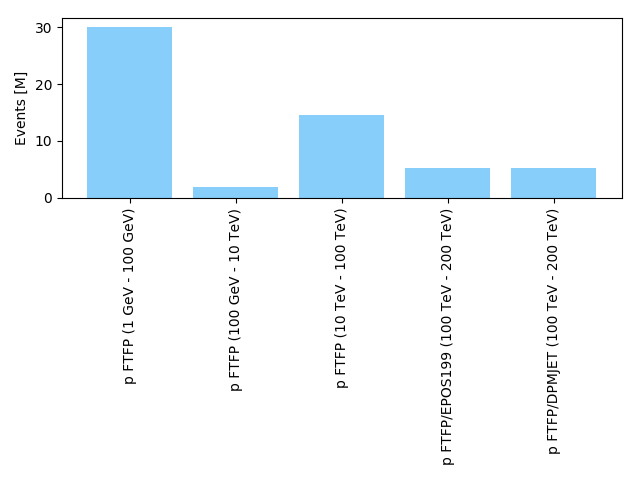
- contributions/dampe/figureCNAF2018.png 0 additions, 0 deletionscontributions/dampe/figureCNAF2018.png
contributions/chnet/metadataSchema.png
0 → 100644
{kind=link}

31.6 KiB
contributions/cnprov/cnprov.tex
0 → 100644
contributions/cnprov/cnprov.tex.bak
0 → 100644
contributions/cover/cover.pdf
0 → 100644
File added
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
contributions/cuore/.gitkeep
0 → 100644
contributions/cuore/cuore.bib
0 → 100644
contributions/cuore/cuore.tex
0 → 100644
contributions/cupid/.gitkeep
0 → 100644
contributions/cupid/cupid-biblio.bib
0 → 100644
contributions/cupid/main.tex
0 → 100644
contributions/dampe/.gitkeep
0 → 100644
contributions/dampe/CNAF_HS06_2017.png
0 → 100644
{kind=link}
62.5 KiB
contributions/dampe/dampe_layout_2.jpg
0 → 100644
{kind=link}
84.1 KiB
contributions/dampe/figureCNAF2018.png
0 → 100644
{kind=link}
20.2 KiB