Showing
- contributions/tier1/disk2018.png 0 additions, 0 deletionscontributions/tier1/disk2018.png
- contributions/tier1/pledge.png 0 additions, 0 deletionscontributions/tier1/pledge.png
- contributions/tier1/tape2018.png 0 additions, 0 deletionscontributions/tier1/tape2018.png
- contributions/tier1/tier1.tex 230 additions, 0 deletionscontributions/tier1/tier1.tex
- contributions/transfer/transfer.pdf 0 additions, 0 deletionscontributions/transfer/transfer.pdf
- contributions/user-support/main.tex 11 additions, 10 deletionscontributions/user-support/main.tex
- contributions/virgo/AdV_computing_CNAF.tex 20 additions, 20 deletionscontributions/virgo/AdV_computing_CNAF.tex
- contributions/xenon/.gitkeep 0 additions, 0 deletionscontributions/xenon/.gitkeep
- contributions/xenon/main.tex 165 additions, 0 deletionscontributions/xenon/main.tex
- contributions/xenon/xenon-computing-model.pdf 0 additions, 0 deletionscontributions/xenon/xenon-computing-model.pdf
- immagini/.gitkeep 0 additions, 0 deletionsimmagini/.gitkeep
- immagini/Additional-Information_18_web.jpg 0 additions, 0 deletionsimmagini/Additional-Information_18_web.jpg
- immagini/convert_to_pdf.sh 2 additions, 0 deletionsimmagini/convert_to_pdf.sh
- immagini/copertina_web.jpg 0 additions, 0 deletionsimmagini/copertina_web.jpg
- immagini/datacenter_18_web.jpg 0 additions, 0 deletionsimmagini/datacenter_18_web.jpg
- immagini/esperiment_18_web.jpg 0 additions, 0 deletionsimmagini/esperiment_18_web.jpg
- immagini/research_18_web.jpg 0 additions, 0 deletionsimmagini/research_18_web.jpg
- immagini/transfer_18_web.jpg 0 additions, 0 deletionsimmagini/transfer_18_web.jpg
contributions/tier1/disk2018.png
0 → 100644
{kind=link}
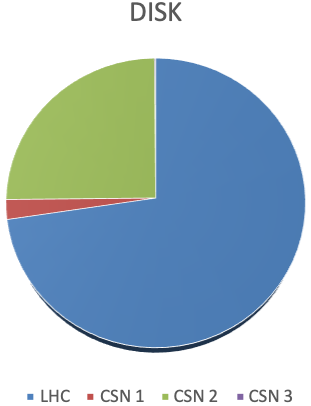
28.4 KiB
contributions/tier1/pledge.png
0 → 100644
{kind=link}
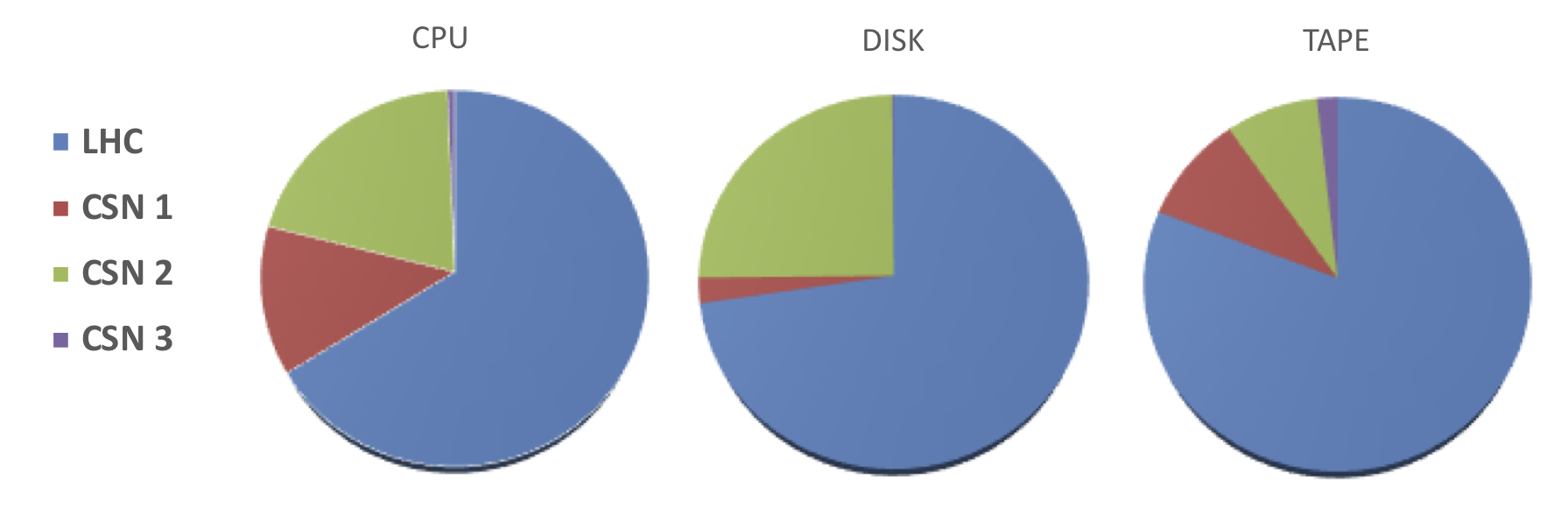
180 KiB
contributions/tier1/tape2018.png
0 → 100644
{kind=link}
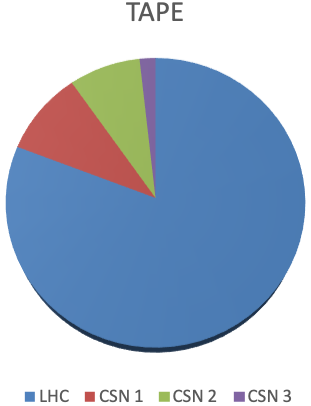
30.2 KiB
contributions/tier1/tier1.tex
0 → 100644
contributions/transfer/transfer.pdf
0 → 100644
File added
contributions/xenon/.gitkeep
0 → 100644
contributions/xenon/main.tex
0 → 100644
File added
immagini/.gitkeep
0 → 100644
immagini/Additional-Information_18_web.jpg
0 → 100644
{kind=link}

752 KiB
immagini/convert_to_pdf.sh
0 → 100755
immagini/copertina_web.jpg
0 → 100644
{kind=link}

2.21 MiB
immagini/datacenter_18_web.jpg
0 → 100644
{kind=link}

846 KiB
immagini/esperiment_18_web.jpg
0 → 100644
{kind=link}

1.87 MiB
immagini/research_18_web.jpg
0 → 100644
{kind=link}

1.39 MiB
immagini/transfer_18_web.jpg
0 → 100644
{kind=link}

1.28 MiB