Showing
- contributions/cta/transfered-data-2018-bysite.eps 5165 additions, 0 deletionscontributions/cta/transfered-data-2018-bysite.eps
- contributions/cuore/.gitkeep 0 additions, 0 deletionscontributions/cuore/.gitkeep
- contributions/cuore/cuore.bib 73 additions, 0 deletionscontributions/cuore/cuore.bib
- contributions/cuore/cuore.tex 73 additions, 0 deletionscontributions/cuore/cuore.tex
- contributions/cupid/.gitkeep 0 additions, 0 deletionscontributions/cupid/.gitkeep
- contributions/cupid/cupid-biblio.bib 114 additions, 0 deletionscontributions/cupid/cupid-biblio.bib
- contributions/cupid/main.tex 63 additions, 0 deletionscontributions/cupid/main.tex
- contributions/dampe/.gitkeep 0 additions, 0 deletionscontributions/dampe/.gitkeep
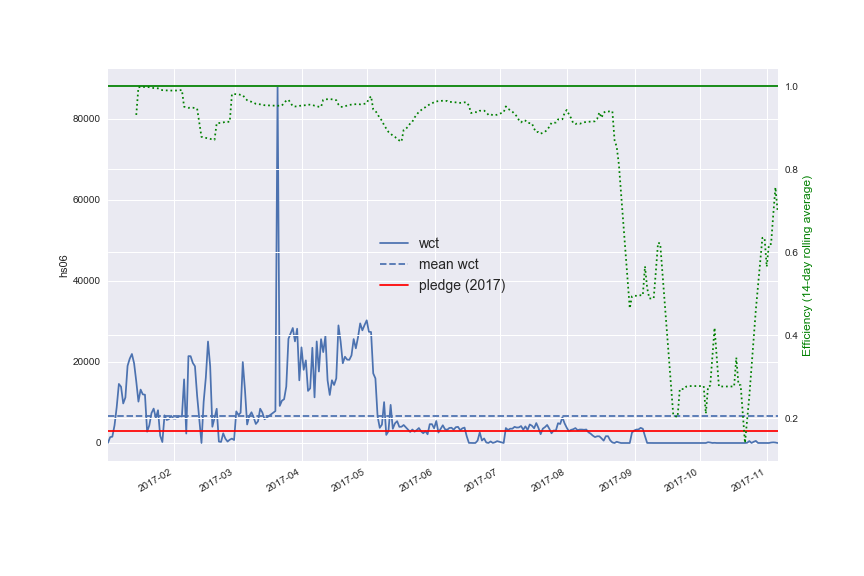
- contributions/dampe/CNAF_HS06_2017.png 0 additions, 0 deletionscontributions/dampe/CNAF_HS06_2017.png
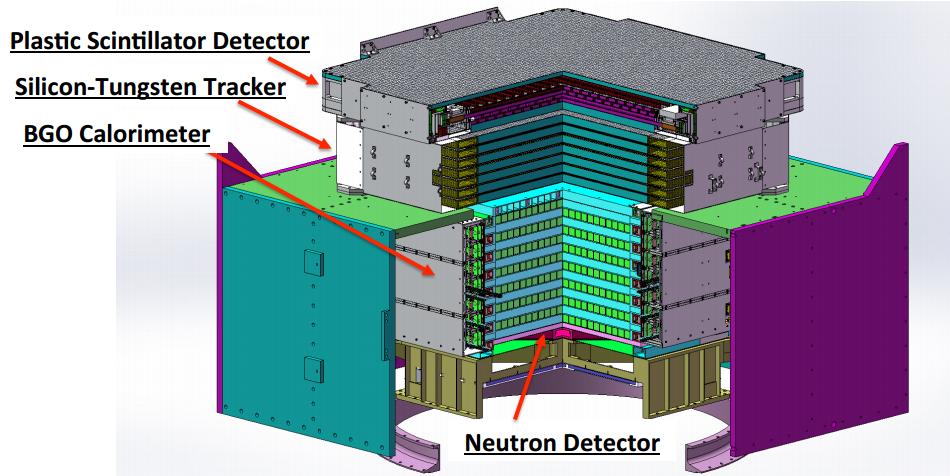
- contributions/dampe/dampe_layout_2.jpg 0 additions, 0 deletionscontributions/dampe/dampe_layout_2.jpg
- contributions/dampe/figureCNAF2018.png 0 additions, 0 deletionscontributions/dampe/figureCNAF2018.png
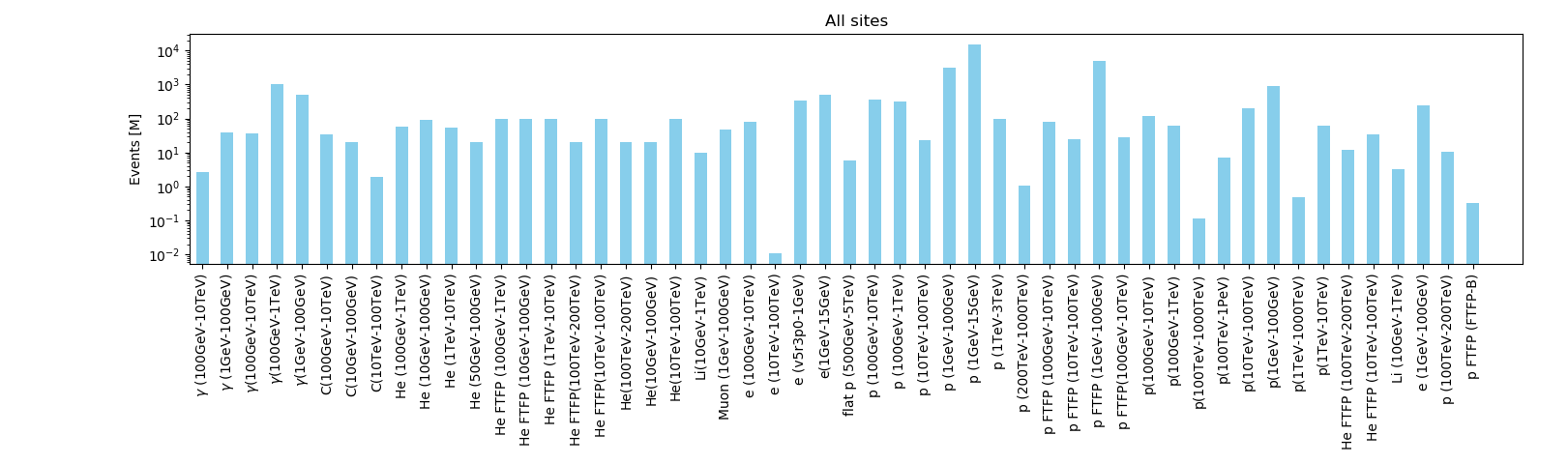
- contributions/dampe/figure_all.png 0 additions, 0 deletionscontributions/dampe/figure_all.png
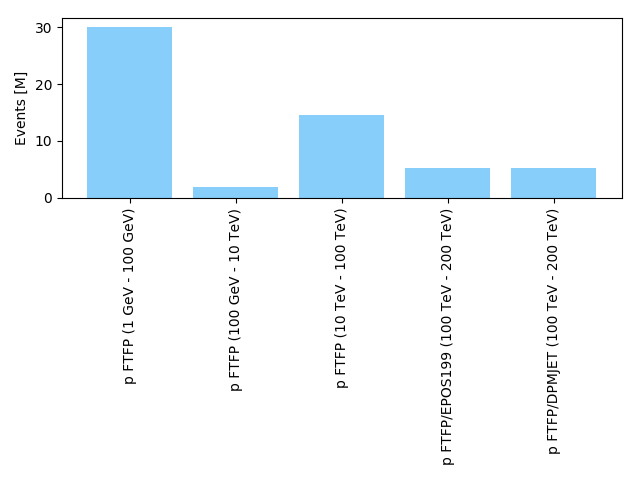
- contributions/dampe/figure_cnaf.png 0 additions, 0 deletionscontributions/dampe/figure_cnaf.png
- contributions/dampe/main.tex 169 additions, 0 deletionscontributions/dampe/main.tex
- contributions/darkside/.gitkeep 0 additions, 0 deletionscontributions/darkside/.gitkeep
- contributions/darkside/ds-annual-report-2019.tex 72 additions, 0 deletionscontributions/darkside/ds-annual-report-2019.tex
- contributions/datacenter/datacenter.pdf 0 additions, 0 deletionscontributions/datacenter/datacenter.pdf
- contributions/dmsq/ar2018.bib 1021 additions, 0 deletionscontributions/dmsq/ar2018.bib
- contributions/dmsq/dmsq2018.tex 597 additions, 0 deletionscontributions/dmsq/dmsq2018.tex
- contributions/ds_cloud_c/Artifact/ds_cloud_c.pdf 0 additions, 0 deletionscontributions/ds_cloud_c/Artifact/ds_cloud_c.pdf
Source diff could not be displayed: it is too large. Options to address this: view the blob.
contributions/cuore/.gitkeep
0 → 100644
contributions/cuore/cuore.bib
0 → 100644
contributions/cuore/cuore.tex
0 → 100644
contributions/cupid/.gitkeep
0 → 100644
contributions/cupid/cupid-biblio.bib
0 → 100644
contributions/cupid/main.tex
0 → 100644
contributions/dampe/.gitkeep
0 → 100644
contributions/dampe/CNAF_HS06_2017.png
0 → 100644
{kind=link}
62.5 KiB
contributions/dampe/dampe_layout_2.jpg
0 → 100644
{kind=link}
84.1 KiB
contributions/dampe/figureCNAF2018.png
0 → 100644
{kind=link}
20.2 KiB
contributions/dampe/figure_all.png
0 → 100644
{kind=link}
85.1 KiB
contributions/dampe/figure_cnaf.png
0 → 100644
{kind=link}
41.1 KiB
contributions/dampe/main.tex
0 → 100644
contributions/darkside/.gitkeep
0 → 100644
contributions/datacenter/datacenter.pdf
0 → 100644
File added
contributions/dmsq/ar2018.bib
0 → 100644
contributions/dmsq/dmsq2018.tex
0 → 100644
File added